批流一體大數(shù)據(jù)分析架構(gòu)的設(shè)計(jì)與實(shí)現(xiàn)
在當(dāng)今數(shù)據(jù)驅(qū)動的時代,企業(yè)對數(shù)據(jù)處理能力的要求日益提高。批流一體架構(gòu)能夠同時處理實(shí)時數(shù)據(jù)和批量數(shù)據(jù),為企業(yè)提供快速、準(zhǔn)確的數(shù)據(jù)洞察。本文將介紹批流一體大數(shù)據(jù)分析架構(gòu)的搭建流程,重點(diǎn)涵蓋數(shù)據(jù)處理和存儲支持服務(wù)的設(shè)計(jì)。
1. 架構(gòu)概述
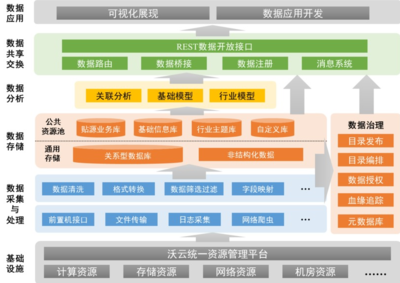
批流一體架構(gòu)融合了批量處理和流式處理的優(yōu)勢,通過統(tǒng)一的數(shù)據(jù)模型和工具鏈,實(shí)現(xiàn)數(shù)據(jù)的統(tǒng)一采集、處理與存儲。核心思想是構(gòu)建一個既能處理歷史批量數(shù)據(jù),又能處理實(shí)時數(shù)據(jù)流的平臺,使得數(shù)據(jù)分析任務(wù)能夠無縫切換或并行執(zhí)行。
2. 數(shù)據(jù)處理層設(shè)計(jì)
數(shù)據(jù)處理層是批流一體架構(gòu)的核心,負(fù)責(zé)數(shù)據(jù)的接入、清洗、轉(zhuǎn)換和計(jì)算。常見的組件包括:
- 數(shù)據(jù)接入工具:如Apache Kafka或Pulsar,用于實(shí)時數(shù)據(jù)流接入;Apache Sqoop或Flume可用于批量數(shù)據(jù)導(dǎo)入。
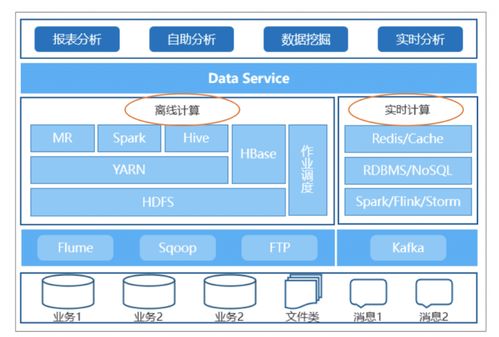
- 計(jì)算引擎:推薦使用Apache Flink或Spark,它們天然支持批流統(tǒng)一處理。Flink以其低延遲和狀態(tài)管理能力著稱,適合復(fù)雜的實(shí)時計(jì)算;Spark則提供強(qiáng)大的批處理能力,并通過Structured Streaming擴(kuò)展流處理功能。
- 數(shù)據(jù)處理框架:采用Lambda架構(gòu)或Kappa架構(gòu)。Lambda架構(gòu)結(jié)合批處理和流處理層,適合高可靠性場景;Kappa架構(gòu)則簡化設(shè)計(jì),僅依賴流處理,通過重播數(shù)據(jù)實(shí)現(xiàn)批處理。
在實(shí)施中,需定義統(tǒng)一的數(shù)據(jù)格式(如Avro或Parquet),確保批流數(shù)據(jù)的一致性。例如,使用Flink的Table API或Spark的DataFrame API,編寫統(tǒng)一的SQL或代碼邏輯處理數(shù)據(jù)。
3. 數(shù)據(jù)存儲層設(shè)計(jì)
數(shù)據(jù)存儲層需要支持高吞吐、低延遲的讀寫,并兼容批流數(shù)據(jù)。常見存儲方案包括:
- 實(shí)時存儲:使用NoSQL數(shù)據(jù)庫如Apache HBase或Cassandra,用于快速查詢實(shí)時結(jié)果;緩存系統(tǒng)如Redis可加速熱點(diǎn)數(shù)據(jù)訪問。
- 批量存儲:數(shù)據(jù)湖技術(shù)如Apache HDFS或云存儲(如AWS S3),用于存儲原始批量數(shù)據(jù)和歷史快照。
- 統(tǒng)一存儲層:采用數(shù)據(jù)湖house概念,結(jié)合Delta Lake或Apache Iceberg,提供ACID事務(wù)和版本控制,實(shí)現(xiàn)批流數(shù)據(jù)的統(tǒng)一管理。這些工具支持在同一個存儲系統(tǒng)中處理實(shí)時更新和批量數(shù)據(jù),簡化數(shù)據(jù)治理。
存儲設(shè)計(jì)時,需考慮數(shù)據(jù)分區(qū)和索引策略,以優(yōu)化查詢性能。例如,按時間分區(qū)可加速時間范圍查詢,同時支持實(shí)時流數(shù)據(jù)的追加和批量數(shù)據(jù)的覆蓋。
4. 支持服務(wù)與工具集成
為了確保架構(gòu)的穩(wěn)定性和可擴(kuò)展性,需要集成支持服務(wù):
- 元數(shù)據(jù)管理:使用Apache Atlas或DataHub,跟蹤數(shù)據(jù)血緣和治理,確保數(shù)據(jù)質(zhì)量。
- 調(diào)度與編排:工具如Apache Airflow或Dagster,用于協(xié)調(diào)批處理和流處理任務(wù),實(shí)現(xiàn)自動化流水線。
- 監(jiān)控與告警:集成Prometheus和Grafana,監(jiān)控?cái)?shù)據(jù)處理延遲和資源使用情況,及時發(fā)現(xiàn)問題。
- 安全與權(quán)限:通過Kerberos或Apache Ranger實(shí)施訪問控制,保護(hù)敏感數(shù)據(jù)。
云平臺服務(wù)(如AWS Kinesis for streaming和EMR for batch)可以簡化部署,提供托管解決方案。
5. 實(shí)施步驟與最佳實(shí)踐
搭建批流一體架構(gòu)時,建議按以下步驟進(jìn)行:
- 需求分析:明確業(yè)務(wù)場景,如實(shí)時推薦或歷史報表,確定數(shù)據(jù)處理延遲和準(zhǔn)確性要求。
- 組件選型:根據(jù)團(tuán)隊(duì)技能和基礎(chǔ)設(shè)施,選擇適合的計(jì)算引擎和存儲系統(tǒng)。從小規(guī)模試點(diǎn)開始,逐步擴(kuò)展。
- 數(shù)據(jù)建模:設(shè)計(jì)統(tǒng)一的數(shù)據(jù)模式,使用事件時間處理來對齊批流數(shù)據(jù),避免時間不一致問題。
- 測試與優(yōu)化:模擬高負(fù)載場景,調(diào)優(yōu)資源配置(如并行度和內(nèi)存分配),并實(shí)施數(shù)據(jù)備份和容錯機(jī)制。
- 持續(xù)迭代:通過監(jiān)控反饋,不斷優(yōu)化架構(gòu),適應(yīng)業(yè)務(wù)變化。
批流一體大數(shù)據(jù)分析架構(gòu)通過統(tǒng)一的數(shù)據(jù)處理與存儲層,能夠高效支撐復(fù)雜的數(shù)據(jù)需求。實(shí)施時,注重組件集成和數(shù)據(jù)一致性,將顯著提升企業(yè)的數(shù)據(jù)分析能力。
如若轉(zhuǎn)載,請注明出處:http://www.deewind.cn/product/13.html
更新時間:2026-01-08 02:58:20