河南和之風軟件開發 智能系統開發的創新實踐與行業影響
在數字化浪潮席卷全球的今天,智能系統已成為推動各行各業轉型升級的核心動力。位于中原腹地的河南和之風軟件開發有限公司,憑借深厚的技術積累與前瞻性的戰略眼光,正穩步崛起為智能系統開發領域的創新實踐者與重要貢獻者。本文將探討和之風在智能系統開發方面的核心理念、技術實踐及其對區域乃至全國數字化進程產生的積極影響。
一、 戰略定位:深耕智能,服務多元
河南和之風軟件開發有限公司自成立之初,便確立了以“智能系統”為核心業務的發展方向。公司深刻理解智能化不僅是技術的升級,更是業務流程的重構與效率的飛躍。因此,其業務布局覆蓋多個關鍵領域:
- 企業智能管理平臺:為企業量身定制集成了數據分析、流程自動化與決策支持功能的綜合性管理系統,助力企業實現精細化管理與科學決策。
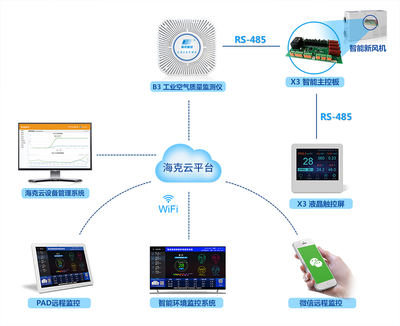
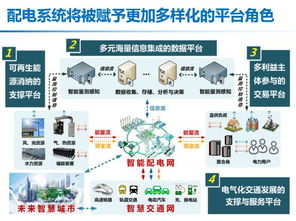
- 物聯網(IoT)與工業互聯網解決方案:結合河南作為制造業大省的特點,開發應用于智能制造、智慧倉儲、設備遠程監控等場景的軟硬件一體化系統,推動傳統產業智能化改造。
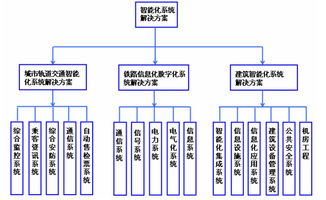
- 智慧城市應用:參與開發城市管理、智慧交通、環境監測等領域的應用系統,為提升城市治理現代化水平貢獻力量。
- 定制化AI解決方案:在圖像識別、自然語言處理、預測分析等方向提供定制化開發服務,滿足客戶特定的智能化需求。
這種多元化布局,使得和之風能夠將智能技術深度融入實體經濟的血脈,實現技術價值與商業價值的有效統一。
二、 技術實踐:創新驅動,扎實穩健
智能系統的開發離不開堅實的技術底座與持續的創新能力。和之風軟件開發在此方面展現出鮮明特色:
- 技術棧與時俱進:積極采用微服務架構、容器化技術(如Docker、Kubernetes)以及主流云計算平臺,確保系統的高可用性、可擴展性與易維護性。在人工智能層面,熟練運用機器學習框架(如TensorFlow、PyTorch)并結合行業知識進行模型訓練與優化。
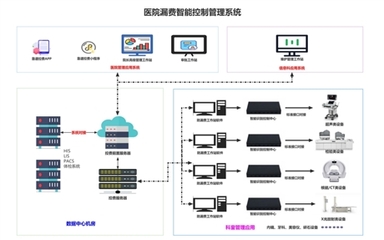
- 注重數據安全與合規:在系統設計中內置安全機制,嚴格遵循數據安全法律法規,特別是在處理敏感信息的系統中,采用加密傳輸、訪問控制等多重防護策略,筑牢安全防線。
- 強調用戶體驗與交互:智能系統不僅是后臺算法的集合,更是與人交互的界面。和之風團隊注重UI/UX設計,致力于打造直觀、高效、人性化的操作體驗,降低系統的使用門檻。
- 全生命周期開發與管理:遵循敏捷開發等現代軟件工程方法論,從需求分析、架構設計、編碼實現、測試驗證到部署運維,提供全流程的專業服務,確保項目高質量交付與持續迭代。
三、 核心優勢與行業影響
河南和之風軟件開發在區域市場中形成了獨特的競爭優勢:
- 本地化深度服務:植根河南,深刻理解本地及周邊區域企業的實際業務痛點、文化環境與政策導向,能夠提供更貼合需求的解決方案和更快速響應的技術服務。
- 成本與價值平衡:相較于一線城市的高成本團隊,和之風在保證技術水準的具備更優的成本控制能力,為客戶提供高性價比的智能系統開發服務。
- 產學研合作:積極與省內高校及科研機構建立合作關系,共同進行技術攻關和人才培養,既提升了自身創新能力,也為區域軟件產業生態注入了活力。
- 推動區域數字化轉型:作為河南本土的軟件技術企業,和之風通過成功項目的示范效應,有力帶動了區域內更多傳統企業和公共部門擁抱智能化,加速了“數字河南”的建設步伐。
四、 未來展望
面對人工智能技術日新月異、產業數字化需求持續爆發的河南和之風軟件開發有限公司將繼續堅守“智能賦能”的初心:
- 深化垂直行業應用:在已涉足的領域做深做透,形成行業標桿解決方案。
- 探索前沿技術融合:密切關注大數據、邊緣計算、數字孿生等技術與智能系統的結合點,保持技術前瞻性。
- 拓展服務廣度與深度:從項目開發向“開發+運營+咨詢”的綜合服務模式延伸,成為客戶長期的數字化合作伙伴。
- 加強品牌建設與區域協同:進一步提升品牌影響力,并尋求與更廣泛的產業鏈伙伴合作,共同做大智能系統應用的市場蛋糕。
###
河南和之風軟件開發有限公司,正如其名,以穩健而創新的“和風”,將智能技術的種子播撒在中原大地。其發展歷程,是本土軟件企業抓住時代機遇、深耕專業領域、服務實體經濟的生動縮影。在智能系統開發的征途上,和之風正以其扎實的技術、務實的風格和前瞻的視野,不僅驅動著客戶價值的提升,也為區域經濟的高質量發展貢獻著不可或缺的科技力量。
如若轉載,請注明出處:http://www.deewind.cn/product/33.html
更新時間:2026-03-07 08:00:02