如若轉載,請注明出處:http://www.deewind.cn/product/24.html
更新時間:2026-03-07 19:08:53
河南和之風軟件開發 智能系統開發的創新實踐與行業影響
從石子加工到砂石骨料行業“小巨人” 智能系統如何驅動產業升級
海克智動 智能系統開發的創新實踐與未來展望
HID 亮相 2025 CPSE 安博會 引領物理門禁新紀元,賦能智能系統開發新未來
基于Java技術的智能停車場管理系統設計與實現
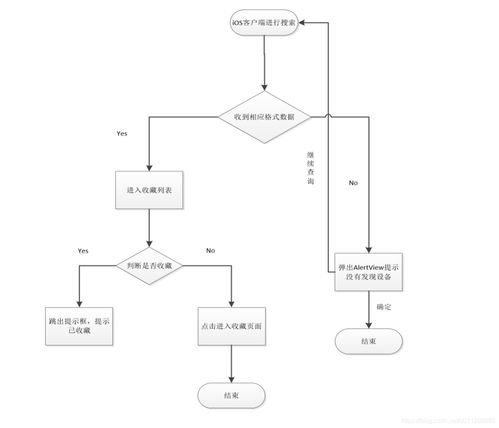
智能家居系統全棧開發 移動端應用與硬件協同的創新實踐
鴻蒙崛起 華為的雄心與谷歌的挑戰
物聯網噩夢 舊設備向新人工智能系統提供過時數據的隱患與挑戰
賽為智能路演 智能系統開發的創新之路與未來展望
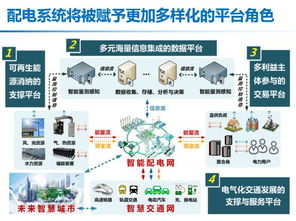
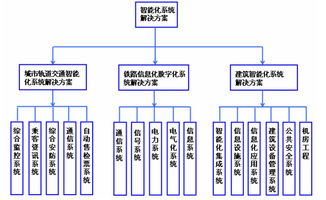
智能配電系統的發展機遇與挑戰
電話:17606338707
地址:山東省青島市城陽區正陽中路160號1號樓1403、1405
Copyright © 2026 www.deewind.cn 智能系統的開發 青島知而行信息科技有限公司 智能系統的開發 版權所有 Sitemap