CSDN博客數據處理與存儲支持服務 技術賦能與高效運維解析

在當今信息爆炸的時代,技術博客平臺不僅是開發者學習與分享的陣地,更是海量數據產生與交互的核心節點。作為國內領先的IT技術社區,CSDN博客承載著數千萬用戶的原創文章、代碼片段、評論互動與個人數據。其背后高效、穩定、安全的數據處理與存儲支持服務,是保障平臺流暢運行、用戶體驗優異及未來持續發展的技術基石。本文將深入解析CSDN博客在這一關鍵支撐體系上的技術實踐與服務架構。
一、 數據處理服務:從產生到洞察的智能流水線
CSDN博客的數據處理服務覆蓋了數據的全生命周期,旨在實現數據的實時性、準確性與價值最大化。
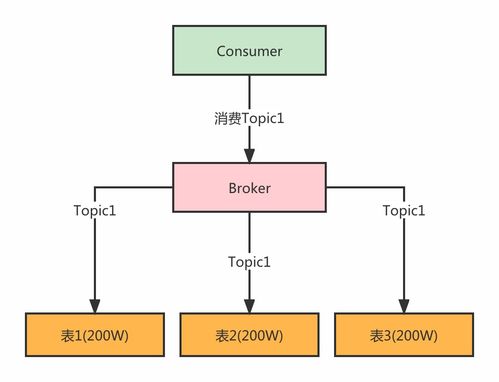
- 實時數據流處理:當用戶發布一篇博客、提交一段評論或點擊一次收藏時,相關事件會通過高吞吐量的消息隊列(如Kafka)被即時捕獲。流處理引擎(如Flink或Spark Streaming)對這些數據進行實時清洗、格式標準化與初步聚合。例如,實時計算文章的初始熱度、更新用戶行為標簽,為個性化推薦提供即時輸入。
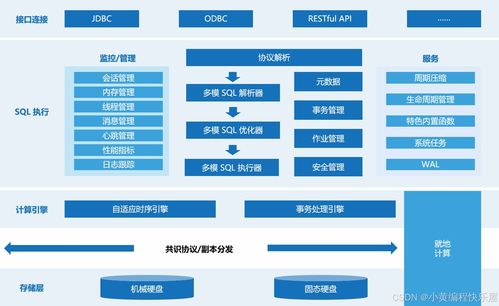
- 批量數據加工與分析:在離線層面,定時的ETL(提取、轉換、加載)作業會將日志數據、業務數據庫快照等導入大數據平臺(如Hadoop或數據湖)。在這里,通過Hive、Spark等工具進行深度分析,生成關鍵報表:如各技術領域的熱度趨勢、博主影響力排名、內容質量評估模型所需的訓練特征等,為運營決策和產品優化提供數據支撐。
- 內容理解與智能處理:利用自然語言處理和機器學習技術,對博客正文進行自動標簽分類、關鍵詞提取、代碼語言識別、相似內容去重及質量初篩。這不僅提升了內容分發的準確性,也有效減輕了人工審核的壓力,并構成了智能搜索與推薦系統的核心能力。
二、 數據存儲服務:多層次、高可用的存儲架構
面對PB級的數據規模和多樣化的訪問模式,CSDN博客采用了分層、異構的存儲策略,以平衡性能、成本與可靠性。
- 在線事務處理存儲:核心用戶數據(賬戶信息、博客元數據、關系數據)存儲在關系型數據庫(如MySQL、PostgreSQL)中,通過分庫分表、讀寫分離、緩存(如Redis)加速等手段應對高并發訪問,確保核心業務的事務一致性與低延遲響應。
- 海量內容與媒體存儲:博客的富文本、Markdown源碼、上傳的圖片等非結構化數據,主要依托對象存儲服務(如自建或云廠商的OSS/S3)。這類存儲具備近乎無限的擴展性、高可靠性和低成本,并通過CDN全球加速,確保用戶無論身處何地都能快速加載博客中的圖片與附件。
- 大數據與歸檔存儲:用于分析的歷史數據、用戶行為日志、冷數據等,存儲于HDFS或低成本的對象存儲歸檔層。這種冷熱數據分離的架構,既滿足了歷史數據分析的需求,又顯著降低了總體存儲成本。
- 緩存與索引存儲:為應對億級內容的瞬時檢索壓力,CSDN博客的搜索功能依賴于Elasticsearch等高性能搜索引擎。多級緩存體系(本地緩存、分布式緩存)將熱點數據(如熱門文章列表、博主信息)置于內存中,極大減輕了后端存儲的壓力,提升了頁面加載速度。
三、 支持服務的核心特性:可靠、安全與可擴展
- 高可用與容災:通過跨機房、跨地域的數據冗余備份與服務部署,實現同城雙活或異地多活。當單一節點或機房發生故障時,系統能自動切換,保障服務不間斷。數據庫主從復制、存儲的多副本機制是這一能力的底層保障。
- 數據安全與合規:服務內置了全方位的數據安全措施,包括傳輸加密(HTTPS/TLS)、靜態數據加密、嚴格的訪問控制與權限管理、操作審計日志以及防爬蟲機制。嚴格遵守數據隱私法規,為用戶提供數據導出與賬戶注銷等權益保障。
- 彈性伸縮與成本優化:利用容器化(如Docker)與編排技術(如Kubernetes),計算資源可根據流量峰谷自動彈性伸縮。存儲層面,通過生命周期管理策略,自動將低頻訪問數據轉移到更經濟的存儲類型中,實現性能和成本的最優平衡。
- 監控與運維:建立從基礎設施、中間件到應用層的全鏈路監控體系(如Prometheus、Grafana),實時追蹤服務健康度、性能指標與錯誤率。結合智能告警與自動化運維腳本,確保潛在問題能被快速發現與修復。
###
CSDN博客的數據處理與存儲支持服務,是一個將數據流、存儲介質與計算資源精密編排的復雜系統工程。它不僅是平臺穩定運行的“沉默守護者”,更是驅動內容智能分發、用戶體驗升級和商業價值挖掘的“智慧引擎”。隨著AI大模型、云原生技術的深入應用,這套支持體系也將持續演進,以更智能、更高效、更安全的方式,服務于每一位在CSDN上創造與求知的開發者,夯實中國開發者生態的數字基礎設施。
如若轉載,請注明出處:http://www.deewind.cn/product/35.html
更新時間:2026-01-06 06:37:44