數據湖存儲格式Hudi 原理、實踐與數據處理存儲服務支持
隨著大數據技術的飛速發展,數據湖已成為企業數據架構的核心組成部分。它旨在存儲海量的原始數據,支持多種數據類型和處理范式。在數據湖的構建中,存儲格式的選擇至關重要,它直接影響到數據的查詢效率、更新能力、事務支持以及存儲成本。Apache Hudi(Hadoop Upserts Deletes and Incrementals)作為一種先進的數據湖存儲格式,以其對增量數據處理、近實時攝取和高效更新/刪除操作的原生支持,在業界獲得了廣泛應用。本文將深入探討Hudi的核心原理,分享其實踐經驗,并闡述其在數據處理與存儲支持服務中的關鍵作用。
一、Hudi的核心原理
Hudi的設計哲學是解決傳統大數據存儲格式(如Parquet、ORC)在支持更新、刪除和增量處理方面的不足。其核心原理圍繞以下幾個方面構建:
- 表類型與查詢類型:Hudi定義了兩種主要的表類型——Copy-on-Write(COW)和Merge-on-Read(MOR)。
- COW表:在寫入時,通過創建包含更新/刪除記錄的新數據文件副本來實現數據修改。查詢時直接讀取最新的數據文件,因此讀取性能最佳,但寫入延遲相對較高,適合讀多寫少的場景。
- MOR表:寫入時,更新和刪除操作被記錄到增量日志文件中,而基礎數據文件保持不變。查詢時需要合并基礎文件和增量日志來提供最新視圖。這種設計實現了低延遲的寫入和高吞吐量的批量讀取,適合寫多讀少的場景。
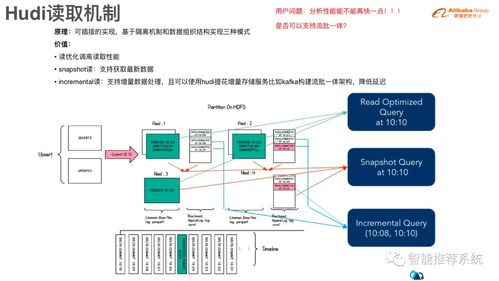
- 時間線(Timeline):這是Hudi的元數據核心,按時間順序記錄了在數據集上執行的所有操作(如提交、清理、壓縮)。它提供了數據集的原子性視圖,并支持時間旅行查詢,允許用戶查詢某個歷史時間點的數據快照。
- 索引機制:Hudi提供了多種索引類型(如布隆過濾器索引、HBase索引、自定義索引),用于在寫入時快速定位一條記錄所在的數據文件。這是高效實現Upsert和Delete操作的關鍵,避免了為更新少量記錄而全表掃描的成本。
- 文件布局與壓縮:Hudi將數據組織成文件組(File Group),每個文件組包含一個基礎數據文件和多個增量日志文件(MOR表)。定期的壓縮操作會將增量日志合并到基礎文件中,優化存儲和讀取性能。
二、Hudi的實踐應用
在實踐中,Hudi能夠有效解決諸多數據工程挑戰:
- 近實時數據攝取:通過流式處理引擎(如Apache Spark Structured Streaming, Apache Flink)可以將Kafka等消息隊列中的數據以極低延遲(分鐘級甚至秒級)寫入Hudi表,構建近實時數據湖。
- 增量ETL與CDC:Hudi原生支持增量查詢,能夠高效地識別出自上次處理以來發生變化的數據。這極大地簡化了變更數據捕獲(CDC)場景下的ETL管道,只需處理增量數據而非全量數據,節省了大量計算資源。
- 支持更新與刪除:對于需要符合GDPR等數據隱私法規,或業務本身需要修正歷史數據的場景,Hudi提供了對記錄級更新和刪除的操作支持,這是許多傳統數據湖格式難以做到的。
- 統一批流存儲:Hudi表可以同時作為批處理和流處理作業的源與目標,實現了存儲層的批流一體,簡化了架構。
典型的技術棧集成包括:使用Apache Spark或Fink進行數據寫入與處理,使用Presto/Trino、Hive或Spark SQL進行交互式查詢,并利用Hudi的元數據同步功能與Hive Metastore集成,使得現有工具可以無縫訪問Hudi表。
三、作為數據處理和存儲支持服務的關鍵組件
在企業級數據平臺中,Hudi扮演著至關重要的數據處理與存儲支持服務角色:
- 提供高效、彈性的存儲服務:通過COW和MOR兩種表類型,Hudi服務可以根據不同的SLA(服務水平協議)要求(讀取延遲 vs 寫入延遲)提供差異化的存儲方案。其自動的文件管理(清理、歸檔、壓縮)功能降低了運維成本。
- 賦能數據管道服務:作為數據管道的關鍵一環,Hudi服務提供了可靠的、具有事務保證的數據接收端點。其增量處理能力使得下游的數據轉換、建模和聚合作業能夠以增量方式運行,構建高效、低延遲的數據流水線。
- 支持數據治理與質量:時間旅行功能為數據審計、回滾和重復計算提供了基礎。更新/刪除能力直接支持了數據糾錯和合規性要求,提升了數據湖的數據質量和可信度。
- 優化計算資源與成本:通過增量處理模式,大幅減少了不必要的數據掃描和計算,直接降低了計算集群的資源消耗和云上成本。高效的列式存儲格式(底層通常為Parquet)也優化了存儲成本。
結論
Apache Hudi通過創新的存儲格式設計,有效彌合了傳統數據倉庫與數據湖之間的能力鴻溝,為大數據生態系統帶來了急需的更新、刪除和增量處理能力。理解和掌握Hudi的原理,并成功將其集成到數據架構的實踐中,能夠幫助企業構建更實時、更高效、更易維護的數據湖,從而為上層的數據分析、機器學習和實時應用提供強大的數據存儲與處理支持服務。隨著數據實時性需求的日益增長,Hudi及其代表的技術方向將繼續在數據湖的演進中扮演核心角色。
如若轉載,請注明出處:http://www.deewind.cn/product/51.html
更新時間:2026-01-06 13:30:52