千萬流量大型分布式系統架構設計實戰 數據處理與存儲支持服務的核心要義

在當今互聯網時代,支撐千萬級甚至億級日活躍用戶(DAU)的系統已成為眾多企業的核心基礎設施。構建這樣一個高并發、高可用的分布式系統,其架構設計尤為關鍵,而數據處理與存儲支持服務更是整個系統的基石與生命線。本文將從實戰角度,深入剖析千萬流量大型分布式系統架構中,數據處理與存儲支持服務的設計理念、核心組件與最佳實踐。
一、架構設計核心挑戰與目標
面對千萬級流量,系統架構設計首要解決的是海量數據、高并發訪問、低延遲響應以及高可用性四大挑戰。數據處理與存儲服務的設計目標因此明確為:
- 高擴展性(Scalability):能夠通過水平擴容(如增加節點)平滑應對數據量和訪問量的指數級增長。
- 高可用性(Availability):確保服務7x24小時不間斷運行,任何單點故障不影響整體服務。
- 高性能(Performance):在毫秒級內完成數據的讀寫操作,滿足用戶體驗要求。
- 數據一致性(Consistency):在分布式環境下,根據業務場景在強一致、最終一致等模型間做出合理權衡。
二、數據處理與存儲服務分層架構
一個穩健的大型系統通常采用分層、分治的設計思想。數據處理與存儲支持服務可抽象為以下三層:
1. 接入與緩存層
這是抵御洪峰流量的第一道防線。
- 負載均衡:采用LVS、Nginx或云服務商提供的SLB,將流量均勻分發至后端服務集群。
- 分布式緩存:核心組件如Redis Cluster或Memcached,用于緩存熱點數據(如用戶會話、熱門內容),將請求攔截在數據庫之外,降低數據庫壓力。關鍵策略包括緩存預熱、多級緩存架構及緩存失效/更新策略(如Cache-Aside、Write-Through)。
2. 計算與消息中間件層
負責數據的異步處理、解耦和流量削峰。
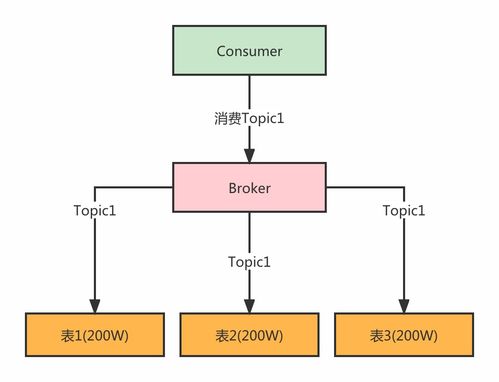
- 消息隊列:Kafka、RocketMQ、Pulsar等是異步化的核心。它們承載日志收集、訂單處理、事件驅動等場景,通過削峰填谷提升系統整體吞吐量和韌性。
- 流式計算平臺:對于實時數據處理需求(如實時監控、風控),Flink、Spark Streaming等組件能夠進行低延遲的流式分析和計算。
3. 持久化存儲層
數據的最終歸宿,根據數據結構與訪問模式進行選型。
- 關系型數據庫:MySQL、PostgreSQL。處理強一致性要求的核心事務數據。實踐中普遍采用分庫分表(如ShardingSphere、Vitess)來突破單庫性能瓶頸,并通過主從復制、讀寫分離提升讀能力和可用性。
- NoSQL數據庫:
- KV存儲:如Redis(持久化)、etcd(配置),用于特定高速訪問場景。
- 文檔型:MongoDB,適合存儲半結構化、模式易變的數據。
- 列式存儲:HBase、Cassandra,擅長海量數據的隨機讀寫與范圍查詢,常用于大數據平臺。
- 時序數據庫:InfluxDB、TDengine,專為監控指標、物聯網傳感器數據優化。
- 對象存儲:如Amazon S3、阿里云OSS,用于存儲圖片、視頻、日志文件等海量非結構化數據,具備近乎無限的擴展能力。
- 大數據存儲:HDFS、Iceberg、Hudi,用于數據湖、離線分析等場景。
三、核心實戰策略與“干貨”
1. 數據庫分庫分表實戰
- 分片鍵選擇:至關重要,應選擇查詢頻繁、數據分布均勻的字段(如用戶ID),避免跨分片查詢。
- 平滑擴容:設計之初需考慮未來擴容方案,可采用一致性哈希等算法減少數據遷移量。
- 全局ID生成:摒棄數據庫自增ID,采用雪花算法(Snowflake)、UUID或分布式ID服務(如Leaf)來保證全局唯一性。
2. 緩存穿透、擊穿、雪崩應對
- 穿透:查詢不存在的數據。解決方案:布隆過濾器(Bloom Filter)快速判定是否存在,或緩存空值(設置短過期時間)。
- 擊穿:熱點Key過期瞬間大量請求直達數據庫。解決方案:互斥鎖(分布式鎖)保證僅一個線程回源重建緩存,或設置邏輯過期時間(永不過期,后臺異步更新)。
- 雪崩:大量Key同時過期。解決方案:給緩存過期時間添加隨機值,避免集體失效;或建立高可用的緩存集群(如Redis Sentinel/Cluster)。
3. 讀寫分離與數據同步
- 利用數據庫原生復制或中間件(如Canal、Maxwell)監聽binlog,將數據變更近乎實時地同步到讀庫或緩存。
- 應用層通過中間件(如MyCat、ShardingSphere)或配置多個數據源來透明化地實現讀寫分離。
4. 數據一致性保障
- 最終一致性主流:大部分互聯網場景可接受短期不一致。通過消息隊列確保緩存與數據庫、數據庫與數據庫間的異步同步。
- 分布式事務:對于強一致性要求的核心交易,可采用TCC、Saga、本地消息表等柔性事務方案,或借助Seata等中間件。
5. 監控與治理
- 全方位監控:對數據庫連接數、QPS、慢查詢、緩存命中率、消息隊列堆積等進行實時監控(Prometheus + Grafana)。
- 容量規劃與彈性伸縮:基于監控指標進行預測,并利用云平臺或Kubernetes實現存儲與計算資源的自動彈性伸縮。
四、
設計千萬流量級別的數據處理與存儲架構,沒有銀彈,只有權衡。關鍵在于深刻理解業務數據模型與訪問模式,靈活組合緩存、消息隊列、各類數據庫等組件,構建一個層次清晰、職責分明、可彈性擴展的技術棧。必須將監控、告警、容災、數據備份與恢復等運維能力融入架構設計的每一個環節。通過持續的性能壓測、故障演練和架構迭代,才能鍛造出真正堅實可靠的數據基石,從容應對流量洪峰與業務增長的挑戰。
如若轉載,請注明出處:http://www.deewind.cn/product/36.html
更新時間:2026-01-06 05:16:22